This is an old revision of the document!
Table of Contents
UTR #50 Review Memo
This page is a memo page to make our discussion on UTR #50 smooth.
Analysis by Codepoint
Codes used for analysis by codepoint:
| Code | UTR50 | MSFT | Meaning |
|---|---|---|---|
| U | U | S | Upright; translates between horizontal and vertical |
| R | S | R | Sideways; rotates between horizontal and vertical |
| TU | T | ST | Typeset upright with alternate glyph. Best fallback is just upright. |
| TR | SB | RT | Typeset upright with alternate glyph. Best fallback is just sideways. |
| V | ? | ? | Upright wrt Unicode code charts, but translates between horizontal and vertical |
Two modes are presented: Stacked (text-orientation: upright) and Mixed (text-orientation: mixed)
| General Category | Stack | Mixed | Memo |
|---|---|---|---|
| Other, Control (Cc) | R | R |  undefined in stacked mode undefined in stacked mode |
| Other, Format (Cf) | R | R | undefined in stacked mode |
| Other, Private Use (Co) | U | U | Bias for East Asian use, since other usage is unknown |
| Other, Surrogate (Cs) | R | R | no need to define? |
| M* | Follows grapheme cluster | ||
| L* and N* | See Letters and Numbers Orientation By Codepoint | ||
| P* and Z* | See Punctuation Orientation By Codepoint | ||
| S* | See Symbols Orientation by Codepoint | ||
Potential categories to support special behavior:
- Math relational operators (equals, greater-than, etc)
- SB brackets
Comparisons
General
- PRI #207 review period ends on Oct 24th, 2011 — way too short
- Eric mentioned that UTR #50 is for Japanese text and should define Hangul orientation that appears in Japanese text, rather than Hangul native orientation. Our goal of “upright-right” is a good vertical text flow for East Asian. Are we seeing things differently?
- UTR #50 only tries “some level of compatibility with existing fonts”. Again, this is very different from our goals, isn't this?
- UTR #50 defines not only glyph orientation in vertical text flow but also character spacing classes in horizontal text flow, similar to what we have in the text-spacing property. Shouldn't this be a separate discussion? Review period is too short for such a big property.
- UTR #50's suggested grapheme clusterization is a) imprecise b) doesn't handle exceptions in Me and Zs categories
- Should add categories for tailorable vs. not tailorable, e.g. Phags-pa and Ideographic are not tailorable to rotate.
- OpenType feature for sideways vertical glyphs would be critical to allow calligraphic and condensed fonts to work with this scheme.
The East Asian Orientation Property
- What are the definitions of U, S, SB, and T? (Tk is gone)
- Which one allows font designers to put alternate glyphs; i.e., UA applies vert feature?
- Maybe most of the following issues are related with the fundamental question: “what are the goals of UTR #50”. If it's for font designers to decide visual glyph orientations to put in vert table, some of these problems are gone, and CSS WG still needs to develop our own algorithm to decide orientation for UAs to render, which could be different from visual glyph orientation.
- From what I understand, T allows anything; from changing glyph to changing orientations, so although “representative glyphs” are shown, their orientations are undefined in UTR #50. Some rotate, some do not, and it's up to font designer. Is this correct understanding?
- If UTR #50 means fonts should not change glyphs/positions for U/S/SB, there are compatibility and font designing problems here.
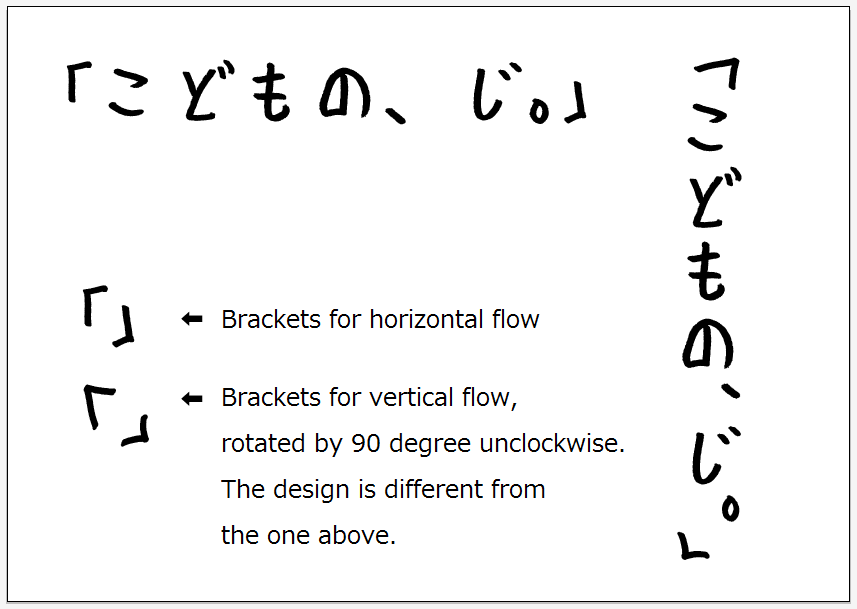
- Some fonts use different glyphs for parenthesis/brackets in vertical flow; e.g., U+FF62/FF63. kodomonoji_20111005-en.png
- Some fonts use U+301D/301F glyphs for U+201C/201D in vertical flow.
- Some fonts use GPOS to adjust positions of punctuation in vertical flow.
- For brush-stroke fonts, start and end edges of strokes (起筆/収筆 in Japanese) vary by flow direction for several glyphs, just like it does for U+30FC, because the direction brush moves is different; e.g., suzuedo.png
- Issues with non-square fonts:
- U does not work with proportional or non-square fonts. If a font is condensed (tall) in horizontal flow, it needs to be condensed (wide) in vertical flow; e.g., AXIS fonts
- S/SB does not work with slanted fonts; e.g., susha.png
- Does the baseline alignment work good by just rotation?
- EM DASH, Arrows, etc. aligns at center baseline?
- Most font designers I contacted believe that it's ok as long as the font is a square font, but I'm worried as it has never been tested at all.
{kind=link}
{kind=link}
{kind=link}
Yi, Mongolian, Hangul, Bopomofo, Egyp
Math
- Fonts seem inconsistent about whether fullwidth characters are upright or sideways. ASCII is sideways.
- Some of them are unified; U+00B1 PLUS-MINUS SIGN, U+00D7 MULTIPLICATION SIGN, U+00F7 DIVISION SIGN, many Sm in U+22xx etc. have full-width glyphs in Japanese fonts and are traditionally upright. Not very comprehensive nor has logical distinction just like other EAW=A though.
- Maybe we could assume MathML are sideways while symbols in text are upright?
Interesting scans:
- Although Han characters within math are sometimes sideways: http://d.hatena.ne.jp/choiyaki/20110908/1315431640 that may be a limitation of the math typesetter: http://fantasai.inkedblade.net/style/scans/ChinatownSFPL013.png http://fantasai.inkedblade.net/style/scans/ChinatownSFPL015.png
- “y” in math are sideways, while “y” in text are upright: http://twitpic.com/2hzi0s
- Equals sign is sideways, even when math is set upright: http://fantasai.inkedblade.net/style/scans/ChinatownSFPL023.png http://fantasai.inkedblade.net/style/scans/ChinatownSFPL027.png http://fantasai.inkedblade.net/style/scans/ChinatownSFPL028.png
- Koji's book with prime/double prime ?vert_math.png
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Tailoring
CSS would need to define some tailorings, should the Unicode spec include them too? E.g.
- upright-cyrillic
- upright-greek
- upright-latin
- upright-letterlike
- sideways-symbols
- upright-math
- upright-numeric
- sideways-unified-punctuation-type-stuff?
The East Asian Class Property
Not reviewed yet.
Comments to Unicode
From the CSS3 Writing Modes editors.
Deadlines
We believe the deadline for comment is too short for such a complex spec. In particular, the new classes will take time to review codepoint-by-codepoint. We hope therefore that Unicode plans to update the spec through multiple review cycles until it stabilizes before publishing UTR50 as a completed spec.
Scope
UTR #50 scopes itself to Japanese layout. However, CSS needs to address all vertical writing systems (i.e. systems in which entire books are written in vertical text, not just used as a graphical effect). If the scope is not broadened to include other writing systems, we cannot rely on UTR#50.
OpenType Features
To force consistency in orientation, UTR#50 expects vert to apply only to T (and maybe SB) category glyphs. However, this is incompatible with many fonts and cannot be implemented by a system that expects to correctly handle legacy content (in other words, any content authored with currently-existing fonts).
We would need to apply vert to the U category as well in order to handle:
- proportional and non-square (compressed) fonts, e.g. AXIS fonts
- cursive fonts
We would need to apply vert to the SB category to handle
- Glyph differences between vertical and horizontal writing in calligraphic / handwriting fonts, e.g. kodomonoji_20111005-en.png suzuedo.png
A new font feature would be needed to apply to the S category to handle
- slanted fonts, e.g susha.png
- potential alignment issues for punctuation
Tailoring
UTR #50 makes no mention of tailoring the orientations. We think the orientation classes should be tailorable; probably Unicode agrees, but this should be more clearly explained.
So that we don't have to manage codepoint-by-codepoint character classes, we'd eventually like UTR#50 to include classes that are commonly tailored / not tailored, that we can reference. Some examples:
- class for characters that are generally not tailored, i.e. vertical-native scripts such as Han, Hangul, Phags-Pa etc.
- class for characters that belong to Western writing systems (typically set sideways) but are often set upright as symbols, i.e. Latin, Greek, and Cyrillic
- brackets, which are pretty much never tailored to upright
- maybe others?
So— registered were mentioned as an issue in UTR#50, and here are samples of copyright symbol copyright_vert.jpg copyright_horz.png
{kind=link}
{kind=link}
Grapheme Clusters
UTR #50 does not provide any rules or pointers to rules about grapheme clusterization. We suggest referencing UAX29 and giving examples of where the boundaries there might adjusted (e.g. in Indian scripts).
The properties of a grapheme cluster should be defined. We suggest that the properties come from the first base character, except in the following cases:
- Grapheme clusters formed with a combining mark of class Me should be treated as So in the Common script.
- Grapheme clusters formed with a base of Zs should belong to category Sk and take their EAW from the space.
See also http://www.w3.org/TR/css3-writing-modes/#character-properties
Miscategorized Scripts
The following scripts should be upright:
- Hangul
- All variants of Egyptian
Yi needs more investigation from someone who knows the language. Older books are written vertically, and seem to be a rotation from the Unicode code charts. However I've seen vertical captions in horizontally-set books printed upright.
Halfwidth Forms
I was informed that halfwidth forms are strongly discouraged in vertical text, and typically set sideways. [?]
Arrows and Box-Drawing
Arrows and box-drawing characters should be set sideways by default, as unlike other symbols, they are usually typeset in spatial relation to other content rather than as a standalone graphic. (The same logic applies to the bracket pieces.)
Box drawing characters are any characters in the U+2500–U+259F range.
Arrows are So characters in the U+2190–U+21FF, U+261A–U+261F, U+2794–U+27BE, U+2B00–U+2B11, and U+2B45–U+2B46 ranges; and Sm characters in the U+27F0–297F and U+2B30–U+2B4C ranges.
Placing arrows into the S category instead of U also relieves concerns about inconsistent arrow orientations due to vert interpretation.
Superscripts, Subscripts, Bracket Pieces
We concur with the comments that suggest changing superscripts, subscripts, and bracket pieces to S by default.
Math
Because of the following reasons:
- digits are typeset sideways by default
- commonly used variable names (Latin, Greek) are typeset sideways by default
- superscripts and subscripts are typically typeset sideways
- arrows, which function as relations in math, would also be typeset sideways by default (see above)
- ASCII math symbols are expected to typeset sideways
- mathematical formulae are usually typeset sideways even in vertical text
- the most commonly-used symbols that are intermixed with prose (× and +) are symmetric wrt rotation, and the equals sign (
=) seems to be typeset sideways even when everything else is upright (example)
we suggest math symbols should be typeset sideways by default.
When intermixed in prose, variable names are often typeset upright, and in such styles math symbols might also be typeset upright. However in these situations some tailoring is necessary for the variable names whatever the mathematical default, so using this style to determine the default rules in plaintext does not make sense.
The default orientation of fullwidth math symbols is less clear; perhaps they should be U/T (for equals).